


April 16, 2026
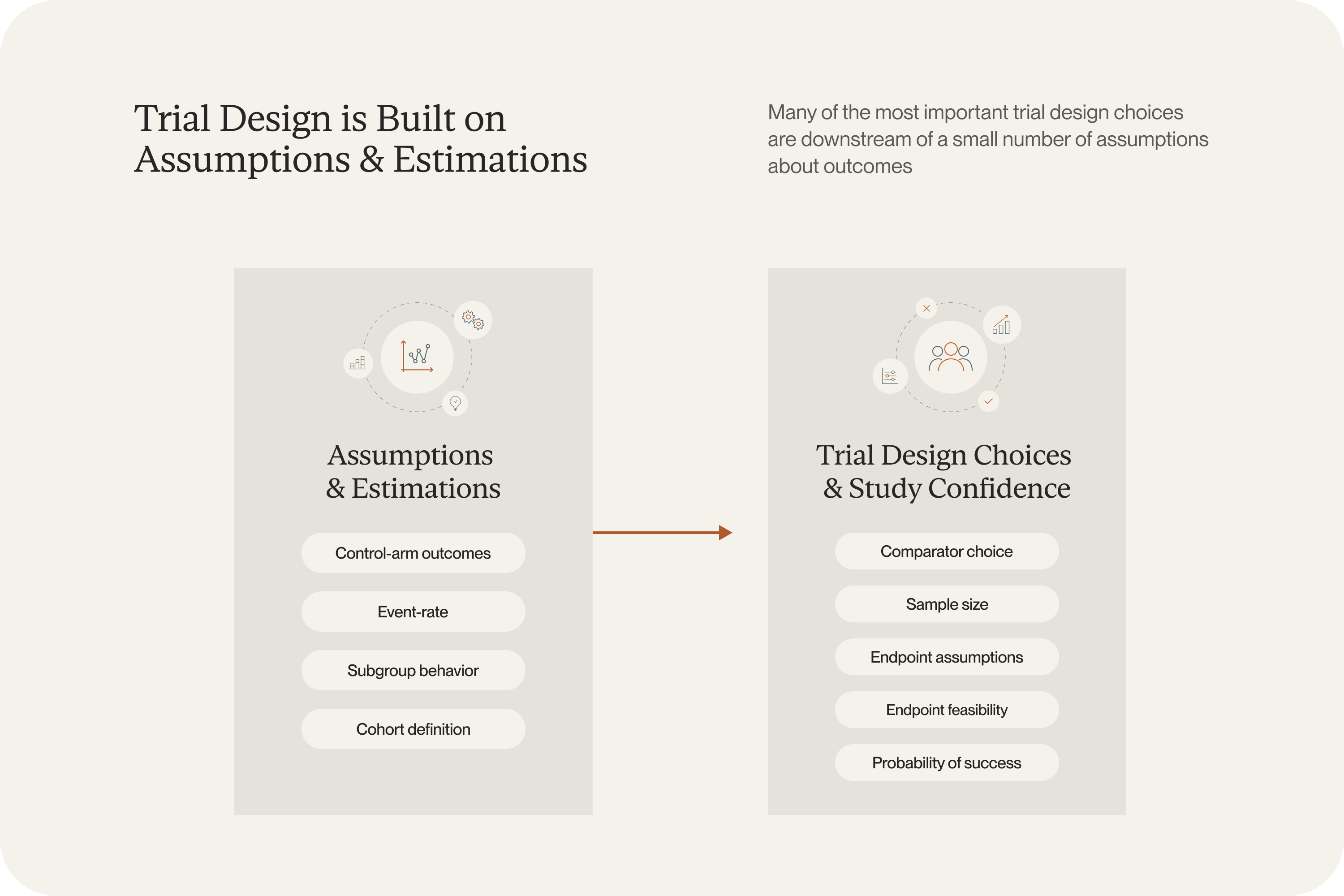
Before an oncology protocol is finalized, most important decisions have already been made based on untested assumptions.
What happens if the eligibility criteria narrow from all KRAS mutations to KRAS G12C only? Does that improve the chance of seeing a signal, or just make the study harder to enroll? How much confidence does a team really have in the event-rate and power assumptions built into the design?
These are the questions that determine whether a trial enrolls smoothly or turns into an expensive amendment exercise later. They’re also the questions governance will likely push back on. A team that has run six scenarios will have more defensible results.
In our first and second blog posts in this series, we described why these assumptions are harder to get right and how a trial-calibrated modeling approach can help. The next question is the practical one: what does that actually change in the study-design workflow?
It means a team can ask “what happens if we narrow to KRAS G12C?” or “what does the control arm look like under the current standard of care?” and get a calibrated answer before the protocol is finalized.
What trial simulations for oncology mean in practice
Here’s how it works. The inputs are the same ones a real protocol depends on: inclusion and exclusion criteria, baseline characteristics, biomarker definitions, line of therapy, and treatment regimen. Once those are specified, the model can generate a cohort that reflects the trial a team is actually trying to run and estimate how outcomes may change as those design choices change.
This is the practical output of the FRESH modeling approach described in part two of this series. Because the model is calibrated to published trial results rather than built from a dedicated data study, the simulations are ready to go quickly. Teams do not need to commission a large real-world dataset to test different cohort definitions or comparators. The model generates calibrated, patient-level predictions for each scenario.
That gives teams more room to explore during the design phase.
.png)
Questions you can answer before protocol finalization
1. What should we expect from the control arm?
This is often the hardest question to answer cleanly. Standards of care evolve quickly, and published trial results remain the most credible source of evidence, but they are reported for specific historical populations and treatment contexts, not for the exact cohort a new study hopes to enroll.
Because the FRESH modeling approach calibrates predictions to published trial results and operates at the patient level, teams can estimate expected control arm outcomes for the specific cohort they are designing around, including narrow biomarker-defined populations where comparable historical datasets may not exist or be accessible.
2. How much does the design depend on the cohort definition?
Eligibility criteria often look like a clinical choice, a regulatory choice, or a feasibility choice. In practice, they are all three at once.
Narrowing a cohort may strengthen the biological rationale for the study. It may also change the expected event rate, alter the standard-of-care benchmark, affect the sample size, and make enrollment harder.
Take a familiar kind of decision: should a study include all KRAS-mutant patients, or restrict enrollment to KRAS G12C? Or in first-line NSCLC, should a design use one PD-L1 threshold or another?
Those choices shape the trial in ways that are easy to underestimate when only one or two scenarios get examined. Trial simulations make it possible to compare those scenarios directly while design flexibility still exists. Because calibrated predictions can be generated for each scenario without restarting the evidence assembly process, a team can examine several cohort definitions in the time it would previously have taken to commission one.
3. Which subgroup is worth prioritizing?
Oncology teams rarely choose between a good option and a bad one. More often, they are choosing among several plausible paths, each supported by some evidence and some degree of judgment. One subgroup may look biologically cleaner. Another may be easier to recruit. A third may better match commercial or program-level priorities. Those tradeoffs are real, and the supporting evidence is often uneven.
Simulations give teams a way to compare those subgroup strategies using a shared analytical framework. Instead of relying on scattered subgroup readouts, broad historical averages, etc. they can ask how outcomes may differ across several candidate populations before they commit to one. In validation against the POSEIDON trial, the model accurately reproduced differential survival across PD-L1 expression, histology, KRAS, STK11, and KEAP1 status: the same subgroup dynamics that drive these prioritization decisions.
A different relationship with the design process

The operational shift is fewer one-off analyses and more structured exploration.
When a team has access to a large, representative real-world dataset, the preferred quantitative path is clear: acquire the data, shape it into a cohort, and analyze design scenarios directly. In practice, though, most teams face real constraints. The available data may be too small, too expensive, riddled with gaps, or simply not accessible for the population in question, or some combination thereof. The result is that the standard quantitative process often cannot be done well, and teams end up making critical design decisions with less evidence than they’d like.
Calibrated simulations change this. The model generates patient-level cohorts on its own, so a team does not need to commission a separate data study every time they want to test something. That opens up questions that would otherwise be tabled: What if we narrowed eligibility? What happens under a different standard-of-care assumption? What does the effect estimate look like in an older population? Most programs never run those scenarios because the data work alone would take months.
Before the protocol is finalized, a team can now work through far more of those questions inside the model. If a comparator shifts, they can rerun the analysis in hours, (not weeks.) The design conversation improves because the team has actual evidence behind their choices instead of educated guesses about what the data would have shown.
More confidence, earlier
It’s unlikely we’ll ever completely eliminate uncertainty from oncology trial design. But we can discover the weak spots in assumptions during the design phase instead of after it’s already running.
The validation results described in part two of this four-part series bear this out: the model predicted the BREAKWATER control arm without ever training on BREAKWATER data, reproduced subgroup-level survival in the POSEIDON trial, and interpolated accurately to the LEAP-006 regimen using only the KEYNOTE chemotherapy arms as calibration inputs. This approach can be applied to the specific populations, regimens, and cohort definitions a team is actually considering.
We also recently published part four, which tackles a related challenge: how do you compare two established treatments when no head-to-head trial has ever been run — and one likely never will be?
If you’d like to explore how Unlearn’s approach could apply to a specific program or if you have a design question, reach out to our team.





