


September 5, 2023
Our mission at Unlearn is to advance artificial intelligence to eliminate trial and error in medicine. We believe that a key step towards achieving this will be the ability to create digital twins of individual people that forecast their future health outcomes. But, the human body has roughly 100 times as many cells as there are stars in the galaxy, so it seems like a fool’s errand to build patients’ digital twins from mechanistic models with intricate biological detail. That’s why we put so much effort into inventing new types of machine learning architectures capable of learning to simulate patients’ future health outcomes and into curating the world’s best database of longitudinal patient data.
I previously outlined our Top Secret Plan for AI in Medicine, Part 1 with the following four steps:
- Build an AI that can create digital twins of patients in clinical trials, and use it to design more efficient, ethical, and reliable clinical studies.
- Reinvest that money into research and development to improve our AI so that it can also simulate the effects of existing treatments, and use it to power an in silico comparative effectiveness platform.
- Reinvest that money into research and development to improve our AI so that the predictions it makes for treatment outcomes are accurate enough at the individual patient level that they can be used to guide treatment decisions.
- Scale these solutions until we can turn most of medicine into a computational science.
These four steps start with “build an AI” but that’s not quite right. Currently, we’re training AI models—which we call digital twin generators—for specific indications. That is, we create one model for Alzheimer’s disease, another for Parkinson’s disease, a third for Frontotemporal Dementia, and so on. This approach works quite well, relies on innovative machine learning research, and allows us to deliver a lot of value—but I believe it has a ceiling. To smash through that ceiling and scale our solutions across medicine, we are going to create a universal digital twin generator, a single model for all of human health.
I’ve encountered lots of surprise and skepticism at this plan when I’ve mentioned it to friends and colleagues from the medical or life sciences, but those coming from machine learning tend to think it’s completely natural and, frankly, inevitable. If I wanted to build a generative language model to imagine new work of fiction but always written in the style of Shakespeare, would it be better to train a model on (i) only the works of Shakespeare or (ii) a massive dataset of all text that includes all of Shakespeare’s works along with lots of other stuff? The correct answer is (ii). The “lots of other stuff” has tons of information about language, and about the world, that will be useful to the model when it generates new text, even if we ask it to always write new text in the style of Shakespeare. A model trained on just the works of Shakespeare would have no concept of any modern inventions, modern science, modern life, or history after his death in 1616.
Just as stories from different authors share lots of things in common such as grammar, vocabulary, and themes, there are some clear ways in which different diseases also have many things in common. For example, Alzheimer’s Disease and Frontotemporal Dementia are different degenerative neurological conditions, but share enough common symptoms that measures like the Clinical Dementia Rating scale are used in both indications. Psoriasis and Rheumatoid Arthritis have quite different symptoms, but it’s believed both are caused by an autoimmune response in which the body’s immune system starts to attack normal cells. A universal digital twin generator would benefit by learning from these similarities and sharing information across related indications, whereas disease specific models can’t—they are limited by the data you have on the specific indication.
To build our universal digital twin generator, we aim to create a vector space for human health. Just as language models map words like “man”, “woman”, “king”, and “queen” to a vector space where we can perform operations like “king - man + woman = queen”, creating a vector space for human health will allow us to learn the relationships between different diseases and clinical measurements. We imagine that there is some state of every patient which, although it’s not directly observable, defines their current health. We can only get glimpses of this hidden state of health through various phenotypic measurements. If we can figure out how to combine these various glimpses of the hidden state of health, and how to forecast its evolution through time, then we can build a universal digital twin generator.
Sounds difficult, and I suppose it is, but I think it’s just recently become maybe possible. And going after the “just recently maybe possible” is what we live for. So, what do I think the ingredients for a universal digital twin generator are?
The first ingredient is text. Humans store an incredible amount of knowledge in language, and that’s true of our knowledge of biology and medicine as well. Text can tell us that a patient’s score on the Alzheimer’s Disease Assessment Scale Word Recall test is likely correlated to their score on the word recall component of the Mini Mental State Exam. Text can tell us that etiologies of Psoriasis and Rheumatoid Arthritis are similarly due to autoimmune responses. But text cannot get us the entire way.
In addition to text, we will need rich longitudinal data characterizing the phenotypic measurements for a large number of patients from a diverse set indications. To date, we’ve built a dataset of research-quality data from nearly 700,000 patients across dozens of indications—I’m not talking about EMR or claims data, I’m talking about the kind of rich longitudinal data collected in clinical trials and observational research studies. And we’re not going to stop there, we’re not going to stop at 1 million patients, we are going to build the biggest and world’s best source of longitudinal clinical data.
The last ingredient will be novel machine learning algorithms that can combine information from text with a vast and diverse dataset of longitudinal phenotypic measurements to forecast the future health of any person on earth. I’m not going to be too specific on what this algorithm may look like, but at a high level I think it will be something like this:
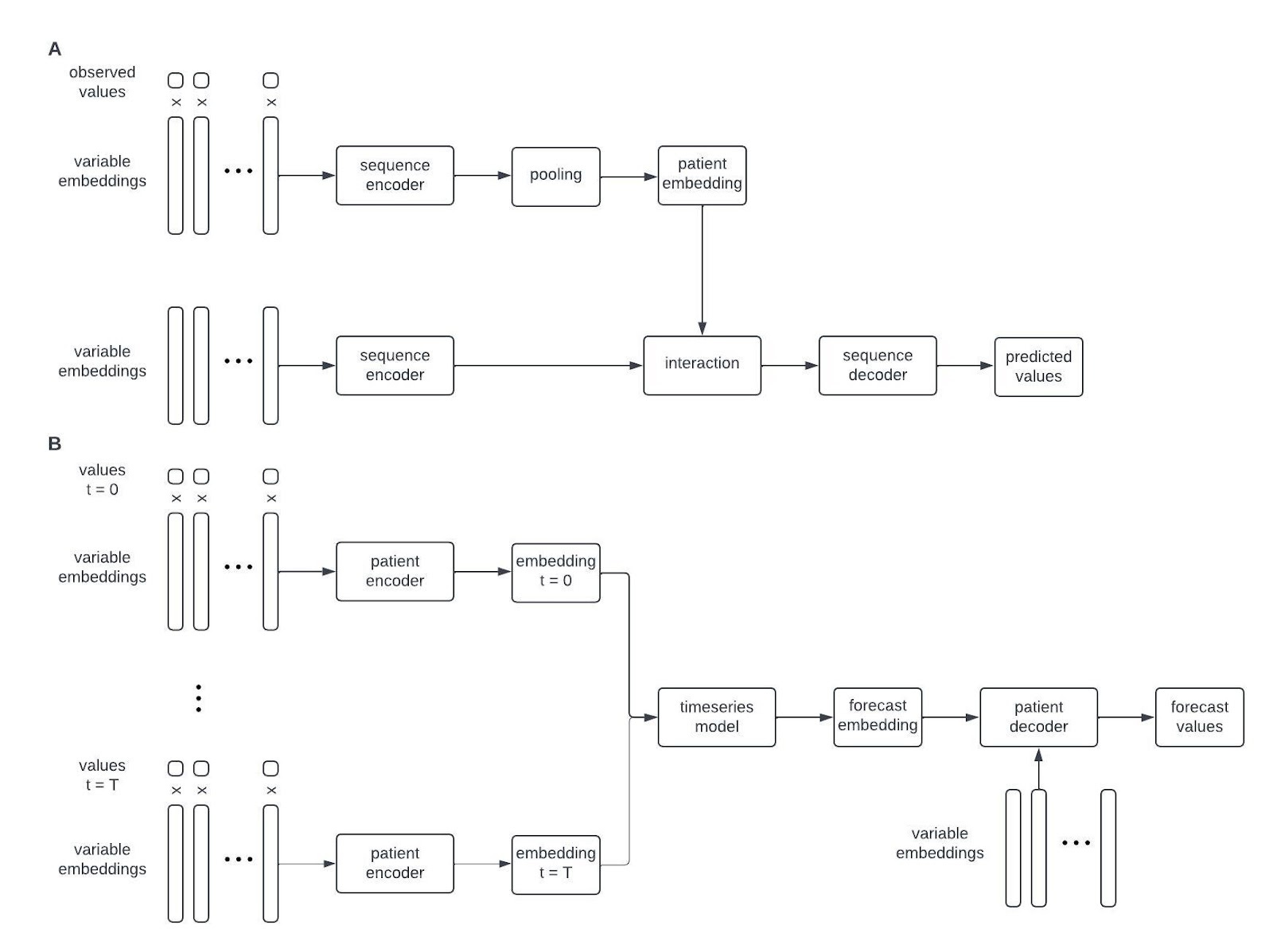
That is, a combination of an encoder-decoder model that maps observed data from a patient onto a universal patient embedding—a high dimensional vector that represents the patient’s health at a particular time—and a time series model that forecasts how the patient’s health will evolve in the future in this hidden space.
We are currently working on building these three ingredients, and when they’re complete we’re going to train a universal digital twin generator and use it to revolutionize all aspects of medicine. In fact, I think we may be able to get a prototype created by the end of the year, but that’ll just be one step in our long and difficult journey to solve AI for medicine. That’s the technical piece of our secret plan.





